Podcast: Play in new window | Download (Duration: 2:05 — 2.9MB)
(: S'inscrire au podcast via une plateforme : Spotify | Deezer | Youtube Music | RSS
[3/30] Responsabilité IA : qui répond quand l’algorithme se trompe ?
Publié le 10 mai 2026 • Temps de lecture : 6 minutes • Article 3 sur 30 de la série Mission d’information Assemblée nationale sur l’IA
La responsabilité IA désigne l’obligation qui incombe aux concepteurs, déployeurs et utilisateurs d’un système d’intelligence artificielle de répondre des erreurs, biais ou préjudices que ce système cause. Lors de son audition à la mission d’information de l’Assemblée nationale, la FFPMI (Fédération Française de la Photographie et des Métiers de l’Image) a posé cette question avec une acuité particulière : quand un modèle d’IA s’entraîne sur des milliers d’œuvres sans consentement, puis produit des images qui concurrencent directement leurs auteurs, qui est comptable de ce préjudice ?
Cette question m’a arrêtée. Pas parce qu’elle relève du droit de la photographie, un domaine éloigné de mon activité de formatrice. Mais parce qu’elle soulève exactement ce que j’évite soigneusement de formuler trop clairement dans mon propre travail : quand j’utilise l’IA pour produire un module de formation, un contenu pédagogique ou une illustration, et que ce contenu comporte une erreur ou un problème, c’est moi qui en réponds. Pas le modèle.
Dans cet article, je tire de cette audition les éléments qui me semblent directement actionnables pour un formateur indépendant. Je laisse de côté les dimensions législatives et les débats sur la réforme du droit d’auteur, qui appartiennent à un autre champ. Ce que je cherche ici, c’est comprendre ce que la question de la responsabilité change concrètement dans ma pratique quotidienne.
[FAQ] Les 5 questions clés sur la responsabilité de l’IA
Si vous arrivez avec une question précise, voici les réponses directes aux interrogations que pose la responsabilité IA aux formateurs et enseignants.
Qui est responsable si une IA fait une erreur ?
La responsabilité repose sur la personne ou l’organisation qui déploie l’IA, pas sur le modèle lui-même. Un modèle d’IA n’a pas de personnalité juridique. Si une IA génère un contenu erroné que vous publiez sans vérification, vous en êtes responsable. Les cadres juridiques européens en cours, notamment l’AI Act, tendent à renforcer cette obligation de supervision humaine pour les usages à risque.
Quelle est la responsabilité en matière d’IA ?
La responsabilité en matière d’IA se répartit entre les concepteurs des modèles, les entreprises qui les intègrent dans des services, et les utilisateurs finaux qui les exploitent. L’audition de la FFPMI et de l’UPP à l’Assemblée nationale pointe un angle souvent négligé : les données utilisées pour entraîner ces modèles ont pu être collectées sans le consentement des créateurs d’origine, ce qui engage la responsabilité des développeurs.
Quelle est notre responsabilité face à l’IA ?
Face à l’IA, notre responsabilité est double. Première dimension : ne pas diffuser de contenu généré sans vérification, qu’il s’agisse d’un texte, d’une image ou d’un module de formation. Deuxième dimension : contribuer à l’éducation à l’image et à la pensée critique, particulièrement en contexte pédagogique. Ce que les intervenantes de la FFPMI et de l’UPP appellent la littératie de l’image est une compétence que les formateurs peuvent développer directement avec leurs apprenants.
Qui est responsable des décisions prises par une IA ?
Les décisions prises par une IA restent sous la responsabilité humaine de celui qui les valide et les met en œuvre. Un algorithme ne décide pas : il produit une sortie en fonction de données d’entrée. La décision effective, celle qui a des conséquences réelles sur des apprenants, des clients ou des partenaires, appartient toujours à la personne qui choisit d’agir sur cette sortie. C’est la distinction fondamentale que les auditions parlementaires cherchent à ancrer dans le droit.
Une image générée par IA est-elle une photographie ?
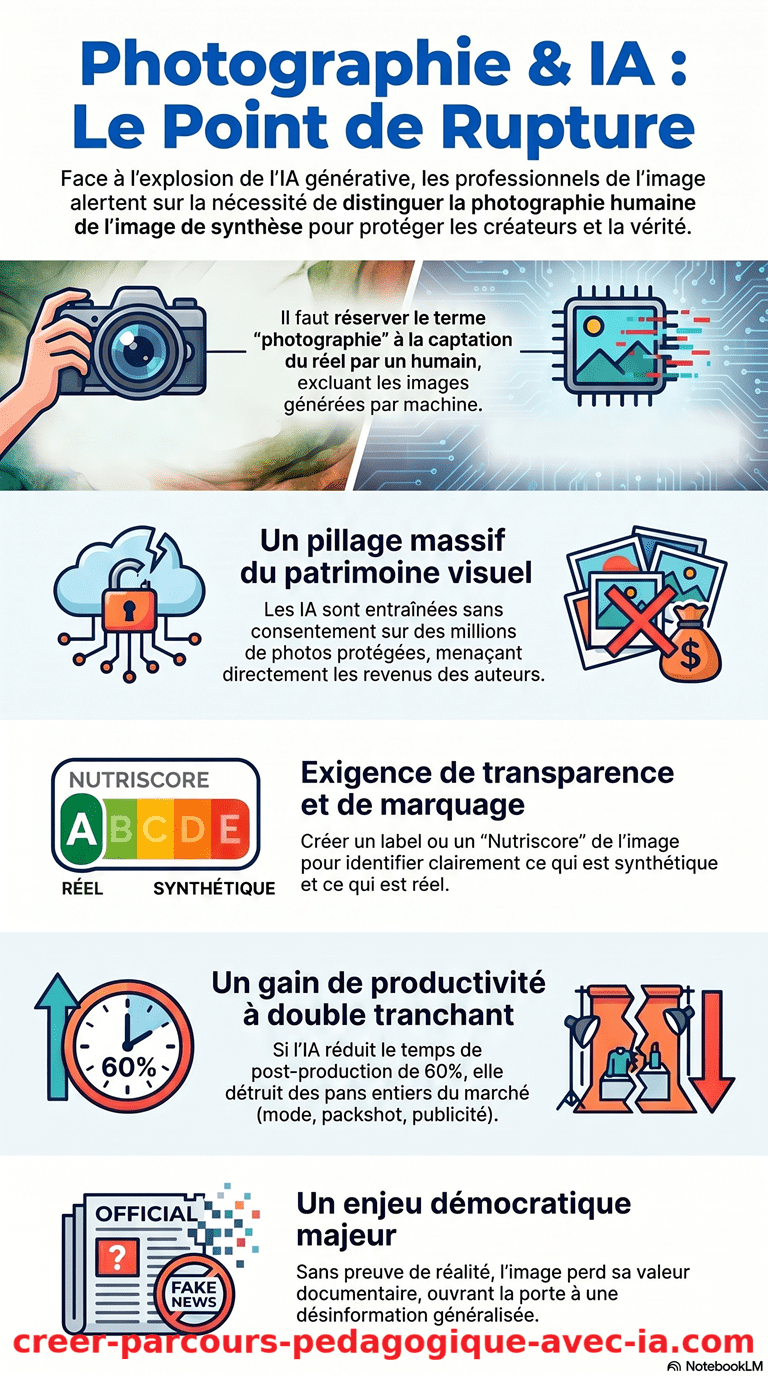
Non. L’UPP (Union des Photographes Professionnels) et la FFPMI plaident à l’Assemblée nationale pour une distinction sémantique et juridique claire entre la photographie, qui capture le réel, et l’image générée par IA, qui produit une représentation synthétique. Cette distinction n’est pas encore formalisée dans la loi française, mais elle a des conséquences pratiques immédiates : utiliser une image générée sans la signaler comme telle, notamment dans un contexte pédagogique ou éditorial, peut induire en erreur et nuire à la crédibilité.
Ce que l’audition révèle : faits et tensions de la séance
Les représentantes de la FFPMI et de l’UPP sont venues à l’Assemblée nationale avec un constat précis : les modèles d’IA générative ont été entraînés massivement sur des fonds photographiques sans consentement des auteurs et sans rémunération. Ce n’est pas une hypothèse. C’est le mode de fonctionnement documenté de la plupart des grands modèles d’image actuels.
Le paradoxe qu’elles soulèvent est édifiant. D’un côté, l’IA offre aux photographes des gains de productivité réels en post-production : retouche automatisée, gestion des lots d’images, génération de variantes. De l’autre, ces mêmes outils, entraînés sur leur travail sans leur accord, sont capables de produire des images de synthèse qui se substituent à la captation du réel dans des domaines entiers, du catalogue produit aux illustrations éditoriales.
Deux demandes concrètes ressortent de l’audition. La première porte sur la transparence : rendre obligatoire la mention explicite qu’une image est générée par IA, aussi bien dans sa diffusion que dans sa commercialisation. La seconde porte sur la distinction sémantique : ne pas appeler « photographie » ce qui n’en est pas une. Ce que l’Assemblée nationale entend ici, selon les intervenantes de l’UPP et de la FFPMI, c’est l’urgence d’une protection législative avant que le marché ne soit structurellement reconfiguré par l’IA au détriment des professionnels de l’image.
En filigrane, les deux organisations insistent sur un troisième enjeu que je trouve particulièrement pertinent pour mon activité : l’éducation à l’image. La multiplication des images synthétiques non signalées affaiblit la capacité des citoyens à distinguer une représentation du réel d’une fabrication. C’est un problème de désinformation, mais c’est aussi un problème pédagogique direct.
Le concept qui change tout : photo réelle et image générée ne sont pas la même chose
La distinction entre photographie et image générée par IA n’est pas qu’une querelle sémantique de professionnels de l’image. Elle a des implications concrètes pour quiconque produit du contenu pédagogique avec des visuels.
Une photographie est une capture : elle atteste que quelque chose a existé, à un moment donné, dans un espace réel. C’est son statut épistémologique fondamental, et c’est ce qui lui confère une force particulière dans les apprentissages. Une image générée par IA est une projection : elle produit ce qui pourrait exister, ou ce qui n’a jamais existé. Elle peut être utile, esthétiquement réussie, pédagogiquement efficace. Mais elle ne dit pas la même chose sur le monde.
Pour un formateur qui illustre ses modules, cette distinction devient une question d’honnêteté intellectuelle. Si j’utilise une image générée pour illustrer un concept, je dois le signaler. Pas pour des raisons légales, même si celles-ci se précisent, mais parce que mes apprenants ont le droit de savoir ce qu’ils regardent. C’est exactement ce que je développe dans mon article sur les outils IA pour les enseignants : l’IA propose, je valide, et je reste responsable de ce que je diffuse.
Ce que ça va changer dans ma pratique
Cette audition m’a conduite à formuler trois décisions concrètes pour ma propre pratique, que je projette d’intégrer systématiquement dans mes livrables à partir de maintenant.
La première concerne la mention des visuels générés. Jusqu’ici, j’utilisais des images générées par IA dans certains de mes modules sans forcément les signaler explicitement. Cette audition m’a amenée à reconsidérer cette pratique. Je compte désormais ajouter une légende ou une mention systématique du type « Image générée par IA » pour tout visuel synthétique inclus dans un contenu que je diffuse, qu’il soit gratuit ou payant. Ce n’est pas une contrainte juridique pour l’instant : c’est une posture éditoriale et pédagogique que je choisis d’adopter.
La deuxième décision porte sur la vérification avant diffusion. J’ai déjà une règle personnelle : je ne publie rien que l’IA a produit sans l’avoir relu et validé. Mais cette audition m’a rappelé que la validation ne porte pas seulement sur l’exactitude factuelle. Elle porte aussi sur la nature du contenu. Une image, un texte ou un module généré peut être factuellement correct et pourtant induire en erreur par ce qu’il donne à voir ou à croire. Cette nuance m’amène à envisager une checklist de relecture plus explicite pour mes productions intégrant de l’IA.
La troisième décision concerne mes livrables clients. Quand je livre un module de formation à un commanditaire, je projette d’intégrer une clause qui précise les outils utilisés dans la production, y compris les outils d’IA, et qui rappelle que la validation finale m’a incombée. Ce n’est pas une décharge de responsabilité : c’est une transparence professionnelle. Elle me protège autant qu’elle informe mon client.
Plus largement, cette séance m’a confirmé quelque chose que je développe dans mon article sur le rôle du formateur digital en 2026 : l’IA n’efface pas la responsabilité humaine, elle la déplace et la précise. Ce n’est plus seulement « ai-je produit un bon contenu ? » mais « ai-je vérifié ce que l’IA a produit pour moi ? »
Ce que je laisse de côté
Cette séance couvre un territoire beaucoup plus vaste que ce que j’ai traité ici. Je n’aborde pas la réforme du droit d’auteur à l’échelle européenne ni les négociations en cours autour de l’AI Act sur le statut juridique des œuvres utilisées pour l’entraînement. Je ne traite pas non plus les modèles économiques alternatifs que les représentantes de l’UPP et de la FFPMI évoquent pour rémunérer les auteurs dont les œuvres ont servi à construire ces modèles. Ces questions relèvent d’un débat de société et d’un processus législatif qui dépasse le cadre opérationnel de mon activité de formatrice.
Si vous souhaitez aller plus loin sur ces dimensions juridiques et économiques, je vous encourage à consulter directement les comptes rendus officiels de la mission d’information de l’Assemblée nationale. C’est précisément pour ça que j’ouvre une série de 30 articles.
Ce que je retiens de cette séance
La question de la responsabilité IA n’est pas un sujet réservé aux juristes ou aux grandes entreprises technologiques. Elle touche tout professionnel qui utilise l’IA pour produire des contenus diffusés à d’autres. En tant que formatrice indépendante, je ne peux pas déléguer ma responsabilité éditoriale et pédagogique à un algorithme. Ce que j’ai produit avec de l’IA reste mon travail, avec les obligations qui s’y attachent.
L’audition de la FFPMI et de l’UPP éclaire cette réalité depuis un angle inattendu : celui des professionnels de l’image, premiers touchés par une reconfiguration radicale de leur marché. Leur demande de transparence et de distinction sémantique est une leçon que je projette d’intégrer dans ma pratique, bien au-delà de la seule question des visuels.
L’article 4/30 de cette série portera sur la prochaine séance de la mission d’information. Vous pouvez également retrouver l’article précédent ici : IA vs humain : ce que l’Assemblée nationale a tranché (2/30).
Identifier vos priorités IA en 2 minutes
Si vous avez l’impression de courir après le temps sans savoir où concentrer vos efforts, cet audit court vous aide à y voir plus clair sur les tâches où l’IA peut réellement vous faire gagner du temps en tant que formateur. Il prend 2 minutes à compléter.
Ou bien si vous êtes sur ordinateur vous pouvez remplir le formulaire plus facilement ci-dessous :
Mon résumé IA en vidéo :
Regarder la vidéo sur YouTube →
Cet article fait partie de la série 30 séances, 30 articles : je lis chaque audition de la mission d’information de l’Assemblée nationale sur l’IA et j’en tire ce qui est concret et actionnable pour les formateurs indépendants.
À lire aussi :
Quelle IA pour les enseignants •
Formateur digital en 2026 : comment l’IA transforme le métier •
Ce post a été coécrit avec Claude. Le préciser sans s’en excuser, c’est aussi une façon de pratiquer ce que je prêche 💪🦾
Asma
J’ai trouvé ton article particulièrement pertinent parce qu’il remet une idée essentielle au centre : utiliser l’IA ne retire pas la responsabilité pédagogique ou humaine. J’ai beaucoup apprécié le fait que tu insistes sur la supervision, le discernement et la validation humaine derrière chaque contenu généré. Le passage où tu expliques que l’IA produit des probabilités et non des vérités absolues est vraiment important à rappeler aujourd’hui. On sent une approche à la fois enthousiaste et lucide, qui évite le piège du “tout automatisé”. Une réflexion très juste et utile.
Merci pour cet article qui clarifie la responsabilité de l’utilisateur d’IA.
Effectivement l’IA restent sous la responsabilité humaine, comme tu le précise , ce n’est pas à l’algorithme de décider à notre place.
Article vraiment intéressant
J’ai beaucoup aimé le fait que tu rappelles que l’IA peut être un outil incroyable… mais qu’elle ne doit jamais remplacer le regard humain, l’esprit critique et la responsabilité pédagogique.
Tu expliques ça de manière très claire, sans tomber ni dans l’enthousiasme aveugle ni dans la peur, et c’est super appréciable
Une fois encore, ton article complet et rigoureux replace bien le cadre. Cette histoire de responsabilité est cruciale. En effet, avec l’IA, il est très difficile de s’assurer de la fiabilité des sources. Je me suis retrouvé plusieurs fois en difficulté à cause de cela (lors de la vente de matériel de musique « vintage » notamment, pour lesquels j’ai fourni des renseignements erronés). Merci pour tes mises en gardes !